I was heavily invested in a note-taking infrastructure during my PhD, using Dokuwiki with a bunch of my own extensions to enable things like extracting and reorganizing content by tags and my own web clipper. However, this workflow was so brittle that I couldn't even manage to transfer it easily to a new laptop, and in the years since that intense bout of literature review (early stage PhD), I've muddled through with a variety of tools, DevonThink, Google Docs, NValt etc.
Recently, I came across Roam Research, and was very excited by how they are combining some of the best ideas of wikis, refining my early idea of reorganizing content through tags, and hierarchical outliners (which I had seen, but never really paid that much attention to - turns out this plus backlinks enables really powerful things). For me, it was an interview that Tiago Forte did with the founder of Roam, Conor White-Sullivan (my notes), which "sealed the deal". I was very impressed by his vision, and have been digging into Roam and the community around it, ever since.
Since then, I've been thinking about the best ways of using Roam, inspired by some of the use cases people have shared (see some in Awesome Roam). I've tried interstitial journaling, keeping track of projects and goals, capturing interesting resources, etc.
I have always been interested in different ways of publishing and sharing my research. With my BA thesis on community libraries in Indonesia, I had it translated to Indonesian, and also made it into an ebook.
I have an extensive page documenting my experiments with my MA thesis on Chinese Open Educational Courses. I made the thesis available in a number of formats, serialized it on my blog, had it translated into Chinese, and also published all of my raw notes (open notebook).
For my PhD thesis, I had big ambitions about having the finished thesis be a live document linking to my notes on all the papers cited (using my Researchr system), but although I wrote my initial drafts in Markdown (with Scrivener), they ended up in Word for collaborative editing and track changes.
I then wanted to create a fancy landing page, with links to resources from the thesis, multiple formats, talks, etc. But after landing in Lausanne, where I am doing a post-doc at EPFL, I never got around to it. Now it has been half a year since I defended my thesis, it is still not public at T-Space, the institutional repository in Toronto, and I decided it's time to set it loose.
Yesterday there was a Twitter discussion about adding a default mailer to Elixir Phoenix (Storify). I've never used the Ruby on Rails mailer, but I got inspired to share my experience with both sending and receiving emails in a recent project.
This summer, I ran a Phoenix server that provided interactive content for an EdX MOOC. One peculiarity of the setup was that authentication happened through the LTI connection with EdX, so there was no need for a sign-up/login form, confirmation of email addresses etc. However, we used email for a number of other purposes.
Sending email
To send email, you need an SMTP server. While Elixir is perfectly capable of handling this on its own, I had heard a lot of stories of how email from private domains might hit spam-filters, and be difficult to configure correctly, so we looked around for an external provider. Amazon Simple Email Service is a no-frills service with a great price-point (currently 0.10$ per 1000 emails). It might not have all the bells and whistles of services like Mailgun and Sendgrid, but for our purposes it worked great.
Amazon SES has a web API, but the easiest way to use it is simply to configure it as an outgoing SMTP server. Looking around, I found the Mailman library, which was easy enough to configure (my code). You simply define a struct like this (storing credentials in a config file):
This summer, I ran a Phoenix server that provided interactive content for an EdX MOOC. Given the geographical distribution of students, the server was getting hit 24/7, and I wanted a quick way to get notified about any error messages. Elixir comes with a built-in logging framework that has several levels of logging (debug, info, warn, error). Any processes crashing will emit error logs, and you can also emit them manually from your own code.
The stock logger only comes with a console backend. I ran the server through Ubuntu's upstart system with a very simple configuration script, which simply set some environment variables and paths, and then used PORT=4000 MIX_ENV=prod mix phoenix.server (I used Nginx to proxy the local port, and add SSL). I used mosh and tmux to keep a persistent connection, and tail -f to watch the upstart log. On the screenshot below, I had several panes tracking both the access log (using plug_accesslog), the Phoenix log, and also a grep on error to see the latest error messages.
Due to BEAM (the Erlang virtual machine) and OTP, Phoenix is remarkably stable. The only time the whole server went down would be because of a serious issue in the datacenter rendering the entire virtual machine inaccessible. Errors were typically bugs that would occur given a certain edge case (for example trying to render the group of a user who had not selected a group yet). They would crash the connection of the user who hit that edge case, but would not propagate up the stack. Thus it would be quite possible for an error to occur and not be noticed, since everything else would continue happily running.
I've been spending the summer in China, head-deep in Elixir, writing interactive scripts for an EdX MOOC on inquiry and technology for teachers (screenshots). I will have much more to share about that project later, but now I wanted to share a small Elixir package I released on Github called Prelude (documentation). This is a collection of utility functions for Elixir that I've extracted out of my code base.
Organization
I began by scattering these utility functions all over as small defps, but when I wanted to reuse them in other modules, I began gathering them. Initially I had a single file called Prelude - modelled after the Haskell Prelude, just because it was the only file I'd ever wholesale import into my other modules.
Eventually I began separating the code out into sub-modules, which meant I went from
import Prelude
map_atomify(...)
to
Prelude.Map.atomify(...)
which seems cleaner.
The point of gathering "trivial" functions
Many of these functions are very simple, but yet things you use all the time - gathering them together both means less repetition and greater legibility. Compare:
The code in the first version is short enough that I wouldn't bother making it a separate function, but the intent of the second snippet is much clearer. I might also forget to do Enum.into(%{}), and somehow I always forget the end in anonymous functions. So, some quick time saving.
I always enjoy finding new ways of automating boring tasks, and today I had a few different small tasks that I was able to solve using some terminal-fu, and Vim macros. I really enjoyed how well it came together, so I thought I'd put together a short screencast to demonstrate.
I had generated a number of discussion forum graphs for different courses. The processed data is in a json file in a directory named after the course. My task was to put an identical index.html file into each directory, create an index of the courses, with links, and modify all the landing pages to reflect the names of the courses. Not a hugely complicated task, but something you could run into day to day, and which would be quite cumbersome to do manually.
The video should be quite self-explanatory, but I've included some "show-notes" below.
As far as I know, ls doesn't have a built-in way to list only directories, so I found this snippet somewhere and added it to my .zshrc:
alias ld="ls -lht | grep '^d'"
awk is a very powerful string manipulation tool, but in this case we're just using it to get the 9th column of each line (awk '{ print $9 }')
I came up with a neat way to embed external web tools into EdX courses using an LTI interstitial, which also allows for rich pedagogical scripting and group formation. Illustrated with a brief screencast.
Last year, I experimented with implementing pedagogical scripts spanning different collaborative Web 2.0 tools, like Etherpad and Confluence wiki, in two hybrid university courses.
Coordinating collaboration and group formation in a class of 85 students was already challenging, but currently we are planning a MOOC built on the same principles. Before we begin to design the pedagogical scripts and the flow of the course, a key question was how much we could possible implement technically given the MOOC platform. Happily, it turns out that it will be easier and more seamless than I had feared.
We chose to go with EdX (University of Toronto has agreements with both EdX and Coursera), which is based on an open-source platform. Open source can mean many different things, there are platforms that are mainly developed privately in a company, and released to the public as periodic "code dumps", and where installation is very complex, and the product is unlikely to be used by anyone else. I didn't know much about the EdX code, but the fact that the platform is already used by a very impressive number of other installations, such as China's XuetangX and France's Université Numérique was already a very positive sign.
One issue that I have not heard much discussion about, is the challenge of finding interesting material in foreign languages. In your own culture and language, you have gotten to know authors through school, through popular media, recommendations from friends, etc. But when you begin exploring a foreign language, it's often like starting from scratch again. I remember walking around in the libraries in Italy, having no idea where to start, or what kinds of authors I might enjoy.
This is made worse by the fact that I am typically much slower at reading in a foreign language, and particularly in "skimming". This means that even though I can really enjoy sitting down with a nice novel, and slowly working through it, actually keeping up with a bunch of blogs, skimming the newspaper every day, or even doing a Google-search and flitting from one page to the next, becomes much more difficult.
Some things are easier these days - it's typically easier to get access to media over the Internet, whether it be movies, podcasts, or ebooks (although this differs a lot between different languages, it is still difficult finding Indonesian movies or TV-shows online, and even Norwegian e-books are hard to come by online), but navigating is still difficult. When I began learning Russian again, I was amazed at the number of very high-quality English blogs that talk about Russian modern literature (places like Lizok's bookshelf, XIX век and Languagehat), which really inspired me to continue working on my Russian, to be able to read the books they so enthusiastically discussed.
R is a very powerful open source environment for data analysis, statistics and graphing, with thousands of packages available. After my previous blog post about likert-scales and metadata in R, a few of my colleagues mentioned that they were learning R through a Coursera course on data analysis. I have been working quite intensively with R for the last half year, and thought I'd try to document and share a few tricks, and things I wish I'd have known when I started out.
I don't pretend to be a statistics whiz – I don't have a strong background in math, and much of my training in statistics was of the social science "click here, then here in SPSS" kind, using flowcharts to divine which tests to run, given the kinds of variables you wanted to compare. I'm eager to learn more, but the fact is that running complex statistical functions in R is typically quite easy. The difficult part is acquiring data, cleaning it up, combining different data sources, and preparing it for analysis (they say 90% of a data scientist's job is data wrangling). Of course, knowing which tests to run, and how to analyze the results is also a challenge, but that is general statistical knowledge that applies to all statistics packages.
I describe a script aimed at supporting student idea convergence through tagging Etherpad content, and discuss how it went when I implemented it in a class
Background
In an earlier blog post I introduced the idea of pedagogical scripting, as well as implementing scripts in computer code. I discussed my desire to make ideas more "moveable", and support deeper work on ideas, and talked about the idea of using tags to support this. Finally, I introduced the tool tag-extract, which I developed to work on a literature review.
Context
I am currently teaching a course on Knowledge and Communication for Development (earlier open source syllabi) at the University of Toronto at Scarborough. The course applies theoretical constructs from development studies to understanding the role of technology, the internet, and knowledge in international development processes, and as implemented in specific development projects.
I began the course with two fairly tech-centric classes, because I believe that having an intuition about how the Internet works, is important for subsequent discussions. I've also realized in previous years that even the "digital generation" often has very little understanding of what happens when you for example send a Facebook message from one computer to another.
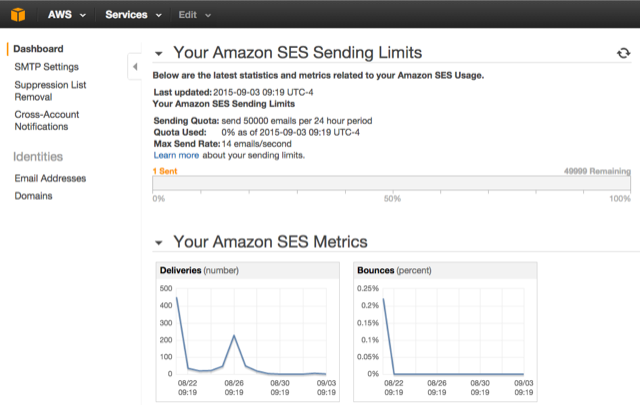 Amazon SES has a web API, but the easiest way to use it is simply to configure it as an outgoing SMTP server. Looking around, I found the
Amazon SES has a web API, but the easiest way to use it is simply to configure it as an outgoing SMTP server. Looking around, I found the 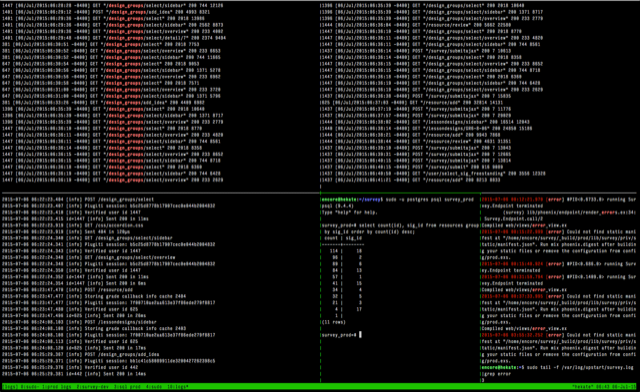


 I am currently teaching a course on Knowledge and Communication for Development (
I am currently teaching a course on Knowledge and Communication for Development (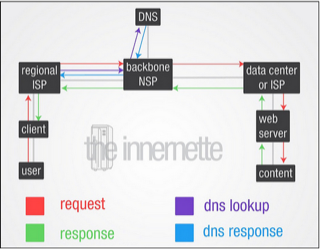 I began the course with two fairly tech-centric classes, because I believe that having an intuition about how the Internet works, is important for subsequent discussions. I've also realized in previous years that even the "digital generation" often has very little understanding of what happens when you for example send a Facebook message from one computer to another.
I began the course with two fairly tech-centric classes, because I believe that having an intuition about how the Internet works, is important for subsequent discussions. I've also realized in previous years that even the "digital generation" often has very little understanding of what happens when you for example send a Facebook message from one computer to another.