Playing with word stemming and frequencies in Russian
October 17, 2013, [MD]
I've been diving back into Russian lately, after many years of neglect (and having never really learnt it in the first place). Much to say about my experiments with DIY parallel texts, my adventure at a Russian supermarket in suburban Toronto, etc, but first some geekery.
Серёжа
 I've been amazed at the amount of people writing (thoughtfully, enthusiastically, beautifully) about Russian literature in English (and other languages), for example Lizok's Bookshelf. In her last entry, Lisa mentioned a book called Seryozha (Серёжа) and a blog post she had written about it, which had attracted a number of comments from India. Color me intrigued, I was very interested to see the number of readers who had enjoyed growing up with this book in Tamil and Bengali (and there was even a Korean reader).
I've been amazed at the amount of people writing (thoughtfully, enthusiastically, beautifully) about Russian literature in English (and other languages), for example Lizok's Bookshelf. In her last entry, Lisa mentioned a book called Seryozha (Серёжа) and a blog post she had written about it, which had attracted a number of comments from India. Color me intrigued, I was very interested to see the number of readers who had enjoyed growing up with this book in Tamil and Bengali (and there was even a Korean reader).
This made me interested in the book itself, so I had a look at the English Wikipedia page (fittingly, the only interwiki link is to Panjabi Wikipedia, looking up the author Vera Panova (Вера Панова), etc. And finally hunting down the book itself (I also tried to find online versions of the English translation, but so far failed).
Stemming/lemmatization
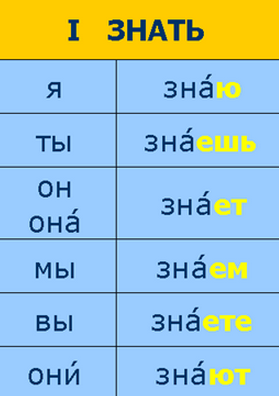 I've just started on another book (a Swedish crime novel in translation), but I was curious about the vocabulary of this book, and since I had it in a beautiful text format, I thought I'd do some quick experiments. Russian words are heavily conjugated, for example the following words that all occur in the text, all mean the same thing (big): большая, больше, большей, большие, большим, большими, большое, большой, большую. Given this, just counting the number of unique words doesn't make much sense, we need to "reduce down" these words to their common roots.
I've just started on another book (a Swedish crime novel in translation), but I was curious about the vocabulary of this book, and since I had it in a beautiful text format, I thought I'd do some quick experiments. Russian words are heavily conjugated, for example the following words that all occur in the text, all mean the same thing (big): большая, больше, большей, большие, большим, большими, большое, большой, большую. Given this, just counting the number of unique words doesn't make much sense, we need to "reduce down" these words to their common roots.
Stemming and lemmatization are two related concepts. Stemming means removing the grammatical suffixes of words, and typically result in strings that are shorter than any dictionary words (for example stemming "ride, rideing, ridden" might turn into "rid, rid, rid"). Lemmatization is similar, but aims to end up with a dictionary entry, ie. "to ride". This would typically be the verb in infinitive form, the noun in singular, etc.
One of the tricky things about looking for open source libraries that deal with Russian, is that most of the information will probably be in Russian (logically). However, since I'm just a beginning learner, looking through technical information in Russian is not an easy task. Luckily, I came across the Snowball stemmer which has stemmers for many languages, including Russian. There are libraries for a number of languages, and I began experimenting with the textmining tools in R, but found the basic stuff too difficult, and moved on to Ruby.
My stemming script in Ruby
I start by importing and defining the stemmer, from the gem ruby-stemmer. I also import the downcase function from unicode_utils - we want to make sure the words are all in the same case, but normal Ruby downcase can only handle ASCII.
require "unicode_utils/downcase"
require 'lingua/stemmer'
stemmer= Lingua::Stemmer.new(:language => "ru")
We read in the file, remove punctuation, downcase it, and split it into words
text = File.read("serezha.txt", :encoding => "UTF-8")
text.gsub!(/[\.\-\_\:\)\(—,\?!«»… ]/,"")
raw_words = UnicodeUtils.downcase(text).split(" ")
We then iterate through the words, stemming, and counting occurences for each stem. We also store the unstemmed words, for later use (I'm using a utility function to add to hash values, see here):
stems = {}
wordvars = {}
raw_words.each do |x|
wrd = UnicodeUtils.downcase(x.gsub(/\s/,"")).strip
stemmedword = stemmer.stem(wrd).strip
stems.add(stemmedword, 1)
wordvars.add(stemmedword, wrd)
end
Now, we grab stems that have more than 10 occurrences, and display some summary statistics.
stems10 = stems.reject {|k, v| v < 10}
puts "Total words: #{raw_words.size}"
puts "Total stems: #{stems.size}"
puts "Stems occurring more than 10 times: #{stems10.size}"
c=0
stems10.each {|k, _v| c = c + wordvars[k].size}
puts "Stems occuring more than 10 times represent #{(Float(c)/raw_words.size).round(2) * 100}% of the text"
Finally, we list the stems with more than 10 occurences, and below, we list each stem, with each unique realization below it (that's where I got my list of большая, больше etc from)
puts "\n\nTop stems:"
stems10.sort_by {|k, v| -v}.each {|k, v| puts "#{k.ljust(20)}#{v}"}
puts "\n\nStems and variants (sorted alphabetically)"
stems10.sort.each do |k, v|
puts "#{k}:"
wordvars[k].sort.uniq.each {|wv| puts " #{wv}"}
end
Result
Once we have this script, we can easily run it on any book (or even on a whole collection of books). Here's a sample of the output from Серёжа:
| Total words: | 26463 |
| Total stems: | 4719 |
| Stems occurring more than 10 times: | 391 |
Stems occuring more than 10 times represent 67.0% of the text
| Stem | Occurrences |
|---|---|
| и | 1292 |
| он | 842 |
| не | 645 |
| в | 524 |
| на | 499 |
| сереж | 474 |
| а | 386 |
(See the whole output here. Looking over the list, I notice that the stemmer is not perfect, although it's far better than working with the raw words.)
Further?
There are many ways I could take this further.
- I could try to hook it up with a dictionary, to generate definitions for all these stems
- I could generate a web page instead of a text file, letting me quickly look through the roots and only pull up definitions for the words I don't know
- Export the list of stems to R and generate graphs of the word frequency
- Find or generate a table over most common stems in Russian (or over a large corpus), and compare that to the frequency in a particular book (does it have many words that are particularly difficult/rare?)
- Automatically generate flash cards or word lists to help with reading
...And I might end up doing some of these. But for now, it was a fun experiment, I'm very happy that there are high quality word stemmers out there (and would love to know about other useful open source Russian language tech), and I'm back to reading my Swedish crime novel in Russian.
Пока!
Stian Håklev October 17, 2013 Toronto, Canada comments powered by Disqus