Opensource Fellowships and localization into Indic languages at SARAI
August 10, 2008, [MD]
Background
![]() I somehow came across the homepage of
Sarai about two years ago, while living in
Indonesia. I was extremely impressed with what I saw from their webpages
and mailing lists - a vibrant community space/collective that was
interested in many of the same things as me; urban issues in developing
countries, open source, open culture, national and regional languages
etc. They publish a ton of great writings, both in English and Hindi,
mostly available from their website, and I downloaded several Sarai
Readers and enjoyed reading
their thoughts on urban development in Delhi, piracy culture, etc.
I somehow came across the homepage of
Sarai about two years ago, while living in
Indonesia. I was extremely impressed with what I saw from their webpages
and mailing lists - a vibrant community space/collective that was
interested in many of the same things as me; urban issues in developing
countries, open source, open culture, national and regional languages
etc. They publish a ton of great writings, both in English and Hindi,
mostly available from their website, and I downloaded several Sarai
Readers and enjoyed reading
their thoughts on urban development in Delhi, piracy culture, etc.
I
also subscribed to their newsletter, and every month I would get an
email telling my about the films they were showing and the talks they
were featuring, thinking it was such a pity that all this interesting
stuff was going on in Delhi, and I was stuck in Toronto… So when I was
finally going to India this summer, for the first time, I knew I wanted
to fit in a visit to Delhi, and to Sarai.
On Friday, having spent two days in Delhi being exhausted from avoiding all the touts in Connaught Place, and walking around in the humidity, I suddenly received an invitation from Sarai to a seminar where all their Open Source Fellows would be presenting their projects. Sarai has been using some of their own money, and also some money from Rajiv Gandhi Foundation, to give fellowships for projects involving open source and localization into Indian languages to groups around India. I was extremely lucky to be able to attend this very interesting gathering, and I learnt a lot from the people there. Here are some of the projects that were presented.
Introduction
 Gora
Mohanty introduced Sarai’s involvement in FLOSS. Originally the
organization mainly focused on urban studies, but they needed tools to
publish in Indian languages, and originally their involvement was more
to “scratch an itch”. They currently have 40 open fellowships, and 10
specific FLOSS fellowships. Based on the experiences from this year,
they will try to provide more support to the fellows, and also promote
more interaction between the different fellows, in future years. A
question related to this is what collaboration technology to be used,
since for example IRC is very convenient for some, but scares others
away. (At the end of day one, I suggested having all the fellows blog,
and then aggregating all the blogs in a planet somewhere). One
experience they have gained is that technical people are often not the
best people to do localization work.
Gora
Mohanty introduced Sarai’s involvement in FLOSS. Originally the
organization mainly focused on urban studies, but they needed tools to
publish in Indian languages, and originally their involvement was more
to “scratch an itch”. They currently have 40 open fellowships, and 10
specific FLOSS fellowships. Based on the experiences from this year,
they will try to provide more support to the fellows, and also promote
more interaction between the different fellows, in future years. A
question related to this is what collaboration technology to be used,
since for example IRC is very convenient for some, but scares others
away. (At the end of day one, I suggested having all the fellows blog,
and then aggregating all the blogs in a planet somewhere). One
experience they have gained is that technical people are often not the
best people to do localization work.
In general, the projects have had a very high success rate, partly explained by the fact that the people who receive the fellowships are often older and more established than for example the Google Summer of Code participants, and have a track record of delivering.
Lately it has become much easier to get funding for doing FLOSS projects in India, since the concept is becoming quite widely known, although perhaps not so well understood by funding agencies still. There is also more and more commercial activity in for example Hindi localization, and many of the projects Sarai fund are more on the “edges”, involving lesser spoken languages, etc.
An example was given of a workshop in Kashmir University, where 100 students showed up. Gora usually starts his presentations by asking how many have used computers before, and then goes on to ask how many have used Windows, etc. However, in this crowd only two people had ever used computers at all before. Yet they came to the meeting and were eager to get involved!
KDE 4.2 localization
 R.
Shrivastava has been working on
localization of KDE 4.2. He also showed off how the KDE applications
work well running natively in Windows. We discussed a bit how to come up
with good terminology in Hindi, since there is a balance between simply
taking all the English words and spelling them in Devanagari (which is
what most cell phone ads in India seem to do), and on the other extreme
use obscure terms for downloading or computer that some government
agency has come up with, but which are very foreign to the users. He
explained that they had tried to strike a balance, using a language that
felt natural.
R.
Shrivastava has been working on
localization of KDE 4.2. He also showed off how the KDE applications
work well running natively in Windows. We discussed a bit how to come up
with good terminology in Hindi, since there is a balance between simply
taking all the English words and spelling them in Devanagari (which is
what most cell phone ads in India seem to do), and on the other extreme
use obscure terms for downloading or computer that some government
agency has come up with, but which are very foreign to the users. He
explained that they had tried to strike a balance, using a language that
felt natural.
We also discussed what kind of tools could be used, especially to access translation memories from other projects, and other languages. Many of the Northern Indian languages are very similar, such as Hindi, Urdu, Punjabi, Marathi, Bhojpuri and Nepali (although with some exceptions written in different scripts). If one is doing a Hindi translation and is stuck on a term, it might thus be useful to be able to quickly look up how they translated it in Punjabi, etc. I am not sure if KBabel for example has this functionality today - it would be useful for other language groups as well, such as Norwegian, Swedish and Danish, or Finnish and Estonian.
Publishing in Indian languages using TeX
 Dr.
C. S. Yogananda is a professor of mathematics, and has often helped
arrange the math olympics. TeX is a publishing package that separates
content from display, and is especially often used in the sciences and
math, because it has powerful capabilities to display mathematical
formulas, etc.
Dr.
C. S. Yogananda is a professor of mathematics, and has often helped
arrange the math olympics. TeX is a publishing package that separates
content from display, and is especially often used in the sciences and
math, because it has powerful capabilities to display mathematical
formulas, etc.
He described how earlier versions of TeX available for Indian languages required a pre-processor, but that he had developed a version that did not, and was thus much easier to use. He has already developed a version in Kannada, and believes that a one week workshop with participants from different language groups would be enough to produce TeX packages for all the Indian languages using the same framework.
He also discussed localization, and his own belief that mere translation was not enough. He took as example GCompris, a package of games for children, and talked about how localization implied changing some games that Indian kids were not familiar with, updating pictures to reflect Indian realities, changing maps so that they were more relevant, etc.
He also talked about early Indian typewriters, stating that if they had been designed from scratch only inspired by the Western models, instead of taking Western models and keeping the same amount of keys, etc, just exchanging for Indic language letters, people might have been much more comfortable typing in Indic languages. (He gave an example from a Supreme Court judge who told that previous to the typewriter, all court deliberations had been in Kannada, but after the advent of the typewriter, it had been so difficult to type in Kannada, that they had switched to English). Even today there are apparently some issues in the Unicode space for Kannada which also makes Kannada computing difficult.
They have been working on Kannada OCR, which is currently 95% finished. Instead of using an existing framework, they started from scratch. Hopefully this will be finished in another 6 months. Finally he showed examples of a Kannada-English dictionary that had been produced using their system, with thousands of pages, and all the indexing etc, using the advanced functionality in TeX. As far as I understood, this dictionary will later be released openly on the web, after a two year exclusivity agreement with a publishing company has lapsed.
One thing that I found peculiar is that the entire input in the TeX source files (which are later processed and turned into PDFs or other output formats) is written not using a Kannada font, but in latin letters - “transcribed”. He insisted that the system for input was logical, and that they were able to input at high speed using this system, but I thought to myself, what if India had invented the computer, and somebody had forced me to input my latest Norwegian poetry, or novel, using Norwegian transcribed into Devanagari alphabet? This concept is still strange to me.
Oriya lexicon
 Dr.
N. M. Pattnaik started out with a fascinating history of dictionaries in
Oriya. The first dictionary dates
back to the 17th Century, and was written for poets. As such, the words
were alphabetized based on the last letters, not the first (to improve
rhyming), and the meanings of each word were given in a poem. In the
18th Century, missionaries started producing dictionaries and grammars
to aid them in their work, but these dictionaries were organized subject
wise. In 1916 the first etymological dictionary in Oriya appeared. Then,
between 1930 and 1940 a gigantic dictionary of 7 volumes and 10,000
pages was produced. This dictionary contained 185,000 head words, with
translations in English, Hindi and Bengali. Unfortunately, only 200
copies were sold, and most of the other copies were destroyed due to
rights disputes with the publisher and the heir.
Dr.
N. M. Pattnaik started out with a fascinating history of dictionaries in
Oriya. The first dictionary dates
back to the 17th Century, and was written for poets. As such, the words
were alphabetized based on the last letters, not the first (to improve
rhyming), and the meanings of each word were given in a poem. In the
18th Century, missionaries started producing dictionaries and grammars
to aid them in their work, but these dictionaries were organized subject
wise. In 1916 the first etymological dictionary in Oriya appeared. Then,
between 1930 and 1940 a gigantic dictionary of 7 volumes and 10,000
pages was produced. This dictionary contained 185,000 head words, with
translations in English, Hindi and Bengali. Unfortunately, only 200
copies were sold, and most of the other copies were destroyed due to
rights disputes with the publisher and the heir.
This amazing dictionary, which is of course an incredibly important part of the linguistic and cultural history, not just of Orissa, but all of India, has been scanned and made available through Pattnaik’s organization. They did it using very simple equipment - a digital camera on a wooden stand, and a huge amount of manual editing and post-processing. The resulting 600 MBs have not yet been put on the internet, but I received a copy, and I will post it to archive.org as soon as I am back in Canada in a few weeks (with good broadband). Sneakernet across the world.
This dictionary represented the peak of Oriya dictionary making, and in the small dictionaries published today, one cannot even find modern words like nuclear or electron. There were also glossaries produced by government committees, but these consisted of scientists that never used Oriya in their own work, and were often were unnatural. In addition, the committees were based on subject field, so a given word, used in many subjects, might be translated differently in every committee.
His organization mainly works on making science fun for kids, and believes that this has to be done in their own language. However, scientists are often not very good in local languages (since most of their education and work happens in English), and so they need good lists of scientific terminology in Oriya and English.
Dr. Pattnaik’s organization generated a database of 20,000 Oriya-Oriya popular words, through the help of science writers who have long experience in popularizing technology and science in the Oriya language. They also produced an English-Oriya dictionary which currently has 6,000 words, and they hope it will reach 15,000 words soon. They will also add explanations in Oriya of terms, and reverse the database to generate an Oriya-English database as well. All this is available in StarDict format, which means that it can be easily used in applications for Mac, Linux, and Windows. As well, they have contributed word lists to aspell, to improve spell-checking for Oriya on Linux.
*Assamese localization of GNOME\ *
This was presented by Gora, since the fellow A. Phukan could not be present. Phukan works with RedHat, which has been doing a lot of localization work, and lately working on an interface for submitting translations through the web (similar to LaunchPad, but perhaps more open source).
Assamese is closely related to Bengali and Oriya, and is spoken in Assam. C-DAC has already done valuable work localizing software, however they don’t work closely with the community, and thus use too formal words that are unnatural to users, and when they are done, just hand off the results and leaves - whereas software localization is something that has to happen continually in a process.
In addition to localization work, Phukan has also created an online dictionary of Assamese, based on user contributions.
Marathi and Urdu User Guide to Open Office
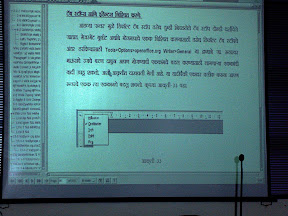 This
was also presented by Gora. Sarvangin Vikas
Sansthan use “reversed rewards” to get localization
done. They post a number of possible jobs they can do on their website,
together with an extremely reasonable price, and they wait for people to
fund them. In this project, they translated the 380+ page user guide to
OpenOffice into Marathi and Urdu. One thing I noticed from the
screenshots was that they were based on non-localized versions of OO.org
(ie. with English menus, etc).
This
was also presented by Gora. Sarvangin Vikas
Sansthan use “reversed rewards” to get localization
done. They post a number of possible jobs they can do on their website,
together with an extremely reasonable price, and they wait for people to
fund them. In this project, they translated the 380+ page user guide to
OpenOffice into Marathi and Urdu. One thing I noticed from the
screenshots was that they were based on non-localized versions of OO.org
(ie. with English menus, etc).
The organization also does a lot of training in OpenOffice an other OSS software in schools in Maharashtra.
I will write about day 2 in a separate post.
Stian
Stian Håklev August 10, 2008 Toronto, Canada comments powered by Disqus